야구에서 득점과 승리의 관계
주제Analyzing Baseball Data with R (3e)을 이용해서 R로 야구 데이터를 분석하는 것을 알아볼 것입니다. 책의 내용 중 4장 The Relation Between Runs and Wins를 따라 하며 야구 분석에 대해 배우고자 합니다. 야
bbdiary03.tistory.com
이번에는 피타고리안 승률을 이용해서 승률을 구해보겠습니다. 피타고리안 승률은 세이버매트릭스의 대부로 여겨지는 빌 제임스가 만든 것으로, 승률을 추정하기 위해 피타고리안 기대승률이라는 다음의 비선형 공식을 도출했습니다.
$$\widehat{Wpct}=\frac{R^2 }{R^2+RA^2}$$
이 공식을 이용하면 R에서 승률을 예측할 수 있습니다.
my_teams <- my_teams |>
mutate(Wpct_pyt = R ^ 2 / (R ^ 2 + RA ^ 2))
여기서는 잔차를 명시적으로 계산해야 됩니다. 하지만 이는 어렵지 않은 작업이고 실제 승률과 예측 승률의 차이를 나타내는 새로운 변수 'residuals_pyt'를 정의하고, 이러한 새로운 예측에 대한 RSME(평균 제곱근 오차)를 비교합니다.
my_teams <- my_teams |>
mutate(residuals_pyt = Wpct - Wpct_pyt)
my_teams |>
summarize(rmse = sqrt(mean(residuals_pyt^2)))
피타고리안 예측으로 계산된 RSME는 선형 예측으로 계산된 RSME와 유사한 값을 가지며, 실제로 사용한 2000 ~ 2023 데이터에서는 약간 더 낮습니다. 그렇다면 복잡한 비선형 모델이 더 정확하지 않다면, 왜 사용해야 할까요?
사실, 피타고리안 기대승률 모델은 선형 모델에 없는 몇 가지 바람직한 속성을 가지고 있습니다. 이 두 가지 장점은 간단한 예시를 통해 설명해 드리겠습니다.
예시 1: 강력한 팀
강력한 팀이 게임당 평균 10점을 득점하고, 평균 5점 가까이 실점한다고 가정해 보겠습니다. 162경기 일정에서 이 팀은 1620점을 득점하고 810점을 실점하여 득실점차가 810점이 됩니다. 이 값을 선형 방정식에 대입하면 승률이 1을 초과하게 되는데, 이는 불가능한 값입니다. 반면 피타고리안 기대승률 공식에 1620과 810을 대입하면 결과는 0.8이 되어 더 합리적인 예측이 됩니다.
예시 2: 완벽한 투수진
또 다른 가상의 팀은 투수들이 절대 점수를 허용하지 않고, 타자들이 항상 필요한 유일한 점수를 득점한다고 가정해 보겠습니다. 이런 팀은 시즌 동안 162점을 득점하고 모든 경기를 승리하게 되지만, 선형 방정식은 이 팀의 승률을 단지 0.601로 예측합니다. 반면, 피타고리안 모델은 이 팀이 모든 경기를 승리할 것이라고 정확하게 예측합니다.
위의 예시들은 현실적이지 않지만, 현대 야구 역사에서 선형 모델의 유용성을 넘어서는 극단적인 상황이 존재합니다. 예를 들어, 2001년 시애틀 매리너스는 116승 46패로 +300 득실점 차이를 기록했고, 2003년 디트로이트 타이거스는 43승 119패로 -337 득실점 차이를 기록했습니다. 이러한 불가능한 시나리오에서 피타고리안 모델은 더 합리적인 승률 예측을 제공합니다.
마지막으로, 득점에서 승리로의 관계는 선수들이 팀의 승리에 기여하는 바를 평가하는데 매우 중요합니다. 선수들이 팀에 기여하는 득점을 추정한 후, 득점-승리 공식을 사용하여 이러한 득점 값을 승리로 변환활 수 있습니다. 예를 들어, "9명의 마이크 트라웃으로 구성된 라인업이 시즌 동안 몇 승을 거둘 것인가?"와 같은 질문에 답할 수 있습니다. 이러한 조사에서는 선형 공식이 깨질 가능성이 더 높으므로, 모든 경우에 합리적인 예측을 제공하는 피타고리안 기대승률과 같은 공식의 필요성이 강조됩니다.
피타고리안 모델의 지수
빌 제임스와 다른 분석가들이 피타고리안 모델을 개선하면서, 처음 제안된 지수값 2보다 더 나은 적합도를 제공하는 지수를 찾고자 했습니다. 이 섹션에서는 실제 승률에 가장 근접한 예측을 제공하는 피타고리안 지수를 찾는 방법에 대해 설명합니다.
위의 식에서 값 2를 미지수로 대체하여 공식을 다음과 같이 작성합니다.
$$\frac{W}{W+L}=Wpct\approx \widehat{Wpct}=\frac{R^k}{R^k+RA^k}$$
약간의 대수학을 사용하여 이 방정식을 다음과 같이 쓸 수 있습니다.
$$\frac{W}{L}\approx \frac{R^k}{RA^k}$$
양변에 로그를 취하면, 선형 관계를 얻을 수 있습니다.
$$log(\frac{W}{L})\approx k\cdot log(\frac{R^k}{RA^k})$$
값을 추정하기 위해 이제 선형 회귀를 사용할 수 있습니다. 여기서 반응 변수는 log(W/R)이고, 예측 변수는 lpg(R/RA)입니다. 다음 R 코드에서는 승/패 비율의 로그, 득점/실점 비율의 로그를 계산하고, 이러한 변환된 변수를 사용하여 단순 선형 모델을 적합시킵니다.(lm() 함수를 호출해서, 우변에 0 항을 추가하여 절편이 없는 모델을 지정합니다.)
my_teams <- my_teams |>
mutate(
logWratio = log(W / L),
logRratio = log(R / RA)
)
pytFit <- lm(logWratio ~ 0 + logRratio, data = my_teams)
pytFit
R 결과에 따르면, 최적의 피타고리안 지수는 1.83으로, 이는 2보다 현저히 작은 값입니다.
피타고리안 모델의 좋은 예측과 나쁜 예측
피타고리안 모델의 예측과 실제 성적의 차이를 이해하기 위해, 2011년 보스턴 레드삭스를 살펴보겠습니다. 피타고리안 모델을 사용하여 레드삭스의 예측 승수를 계산하고, 실제 성적과 비교해 보겠습니다.
2011년 보스턴 레드삭스는 875점을 득점하고 737점을 실점했습니다. 피타고리안 모델의 지수를 2로 설정했을 때, 이들은 95승을 할 것으로 예상되었습니다. 이는 875와 737을 피타고리안 공식에 대입하고 시즌 경기 수로 곱하여 얻은 숫자입니다.
$$162\times \frac{875^2}{875^2+737^2}\approx 95.$$
레드삭스는 실제로 90승을 거두었습니다. 5경기 차이는 레드삭스에게 매우 치명적이었습니다. 그들은 정규 시즌 마지막 경기에 템파베이 레이스에 와일드카드 자리를 내주었습니다. 피타고리안 모델은 같은 시즌의 레이스에 대해서는 더 정확했는데, 707점을 득점하고 614점을 실점한 레이스의 예측 승수는 92승으로, 실제 승수인 91승보다 약간 높았습니다.
피타고리안 공식이 왜 레드삭스에 대해서는 이렇게 부정확했을까요? 즉. 왜 레드삭스는 득점 차이에 비해 예상보다 5승을 더 했을까요? 시즌을 경기별로 살펴보겠습니다.
데이터 프레임 "retro_gl_2011"에는 2011 시즌 동안 모든 경기에 대한 자세한 정보가 포함되어 있습니다. 다음 명령어 파일을 R로 로드하고, 레드삭스 경기에 해당하는 줄을 선택한 다음 득점과 관련된 열만 가져오겠습니다.
library(abdwr3edata)
gl2011 <- retro_gl_2011
BOS2011 <- gl2011 |>
filter(HomeTeam == "BOS" | VisitingTeam == "BOS") |>
select(
VisitingTeam, HomeTeam,
VisitorRunsScored, HomeRunsScore
)
slice_head(BOS2011, n = 6)
보스텀이 참여한 모든 경기의 결과를 사용하여 경기에서 승리했는지 패배했는지 여부를 나타내는 열 W을 추가하고, 경기에서의 득점 차이를 계산합니다.
BOS2011 <- BOS2011 |>
mutate(
ScoreDiff = ifelse(
HomeTeam == "BOS",
HomeRunsScore - VisitorRunsScored,
VisitorRunsScored - HomeRunsScore
),
W = ScoreDiff > 0
)
skimr 패키지의 skim() 함수를 사용하여 경기에서 승리한 경우와 패배한 경우의 득점 차이에 대한 요약 통계를 계산합니다. group_by()에는 그룹화 요인(즉. 경기가 보스턴의 승리로 끝났는지 여부)을 지정합니다.
library(skimr)
BOS2011 |>
group_by(W) |>
skim(ScoreDiff) |>
print(include_summary = FALSE)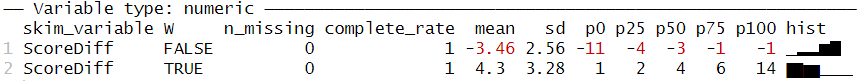
2011년 레드삭스는 평균적으로 승리한 경기에서의 득점 차이가 패배한 경기에서의 득점차이보다 컸습니다. (평균 4.3점 vs -3.5점). 이로 인해 피타고리안 예측보다 5경기 적은 승리를 기록하게 되었습니다. 세이버매트릭스에서는 팀이 피타고리안 승률을 초과 달성하거나 저조하게 달성하는 것을 각각 운이 좋거나 나쁜 것으로 보고, 시즌이 진행됨에 따라 예상 승률에 가까워질 것으로 기대합니다.
팀이 피타고리안 승률을 초과 달성하는 경우, 많은 접전에서 불균형적으로 승리함으로써 발생할 수 있습니다. 이 주장은 간단한 데이터 탐색으로 확인할 수 있습니다. 다음 코드로, 이전에 로드한 2011년 게임 로그에서 팀 이름과 득점이 포함된 데이터 프레임을 생성합니다. 승리팀의 약어를 포함하는 변수 winner와 승리 마진을 포함하는 diff 두 개의 새로운 열을 만들어줍니다.
results <- gl2011 |>
select(
VisitingTeam, HomeTeam,
VisitorRunsScored, HomeRunsScore
) |>
mutate(
winner = ifelse(
HomeRunsScore > VisitorRunsScored,
HomeTeam, VisitingTeam
),
diff = abs(VisitorRunsScored - HomeRunsScore)
)
한 점 차이로 승리한 경기에 초점을 맞춘다고 가정해 봅시다. 한 점 차이로 결정된 경기만 포함하는 데이터 프레임 one_run_wins를 생성하고, n() 함수를 사용하여 각 팀의 그러한 경기에서의 승리 횟수를 계산합니다.
one_run_wins <- results |>
filter(diff == 1) |>
group_by(winner) |>
summarize(one_run_w = n())
이전의 my_teams 데이터 프레임을 사용하여 피타고리안 잔차와 한 점 차이 승리 횟수 간의 관계를 살펴보겠습니다. 주의할 점은 엔젤스 팀의 약어를 변경해야 한다는 것입니다. Lahman 데이터베이스에서는 LAA로, Retrosheet 게임 로그에서는 ANA로 코딩되어 있습니다.
먼저, my_teams 데이터 프레임과 one_run_wins 데이터 프레임을 결합하고 엔젤스 팀의 약어를 조정한 후, 피타고리안 잔차와 한 점 차이 승리 횟수 간의 관계를 분석해 보겠습니다.
teams2011 <- my_teams |>
filter(yearID == 2011) |>
mutate(
teamID = if_else(teamID == "LAA", "ANA", as.character(teamID)
)
) |>
inner_join(one_run_wins, by = c("teamID" = "winner"))
다음 코드는 한 점 차이 승리 횟수와 피타고리안 잔차 간의 긍정적인 관계를 보여주는 그래프를 생성합니다.
ggplot(data = teams2011, aes(x = one_run_w, y = residuals_pyt)) +
geom_point() +
geom_text_repel(aes(label = teamID)) +
xlab("One run wins") + ylab("Pythagorean residuals")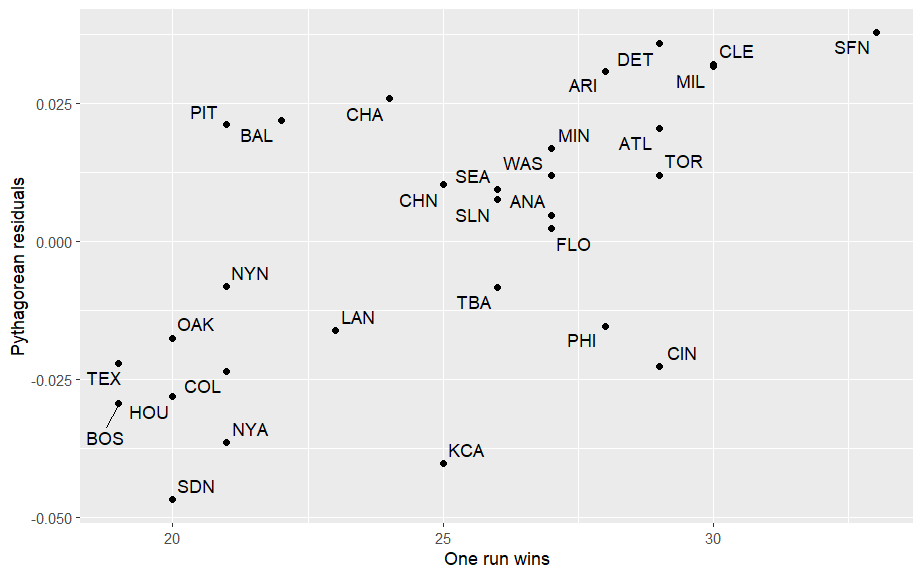
위 그림에서 샌프란시스코가 많은 수의 한 점 차이 승리를 거두었고 큰 긍정적인 피타고리안 잔차를 가지고 있음을 보여줍니다. 반면, 샌디에이고는 한 점 차이 승리가 적었고 잔차가 음수였습니다.
많은 접전에서 승리하는 것은 때때로 단순한 운으로 여겨집니다. 그러나 특정 속성을 가진 팀은 좁은 마진으로 결정되는 경기를 체계적으로 이길 가능성이 더 높습니다. 예를 들어, 최상급 마무리 투수를 보유한 팀은 작은 리드를 유지하는 경향이 있어 피타고리안 예상 승률을 초과 달성할 수 있습니다. 이 가설을 확인하기 위해 데이터를 살펴보겠습니다.
Lahman 패키지의 Pitching 테이블에는 개별 시즌 투수 통계가 포함되어 있습니다. filter() 함수를 사용하여 50경기 이상을 마무리하고 평균 자책점(ERA)이 2.50 이하인 투수 시즌을 선택합니다. 데이터 프레임 top_closers는 투수, 시즌, 팀을 식별하는 열만 포함합니다.
top_closers <- Pitching |>
filter(GF > 50 & ERA < 2.5) |>
select(playerID, yearID, teamID)
top_closers 데이터 프레임을 my_teams 데이터셋과 병합하여 최상급 마무리 투수를 보유한 팀을 포함하는 데이터 프레임을 생성합니다. 그런 다음 summary() 함수를 사용하여 피타고리안 잔차에 대한 요약 통계를 얻습니다.
my_teams |>
inner_join(top_closers) |>
pull(residuals_pyt) |>
summary()
잔차의 평균은 0에 약간 못 미치지만(0.005), 이를 시즌 경기 수(162)로 곱하면 최상급 마무리 투수를 보유한 팀이 피타고리안 모델로 예측된 것보다 평균적으로 0.88경기를 더 승리한다는 것을 알 수 있습니다.
'야구 분석 > R' 카테고리의 다른 글
| 포수 프레이밍이란? (0) | 2024.08.14 |
|---|---|
| 안타와 도루의 가치 (0) | 2024.08.10 |
| 메이저리그 타자들의 득점 기대치 (0) | 2024.08.08 |
| 득점 기대치를 사용한 플레이 가치를 평가해보기 (1) | 2024.08.03 |
| 야구에서 득점과 승리의 관계 (0) | 2024.07.15 |