주제
Analyzing Baseball Data with R의 5장인 'Value of Plays Using Run Expectancy'를 통해 야구 데이터를 분석하는 방법을 배우고자 합니다. 책의 내용을 살펴보면서 각 개념을 이해하고, 실제 데이터를 통해 공부해 볼 것입니다.
득점 기대 행렬
세이버매트릭스에서 중요한 개념은 득점 기대 행렬입니다. 각 베이스(1루, 2루, 3루)에 주자가 있을 수도 있고 없을 수도 있기 때문에, 세 개의 베이스에 주자가 위치할 수 있는 가능한 배열은 8가지입니다. 아웃 수는 0, 1, 2로 세 가지 가능성이 있으므로, 주자와 아웃의 가능한 배열은 총 8 × 3 = 24가지입니다. 각 주자 배치와 아웃 수의 조합에 대해 우리는 이닝의 나머지 부분에서 평균 득점 수를 계산하는데 관심이 있습니다. 이러한 평균 득점 수를 주자와 아웃으로 분류된 표로 배열하면, 이를 종종 득점 기대 행렬이라 부릅니다.
우리는 R을 사용하여 2016 시즌의 플레이별 데이터를 통해 이 행렬을 계삽해볼 것입니다. 이 행렬은 타자의 타석에서 기대 득점 값의 변화를 정의하는 데 사용됩니다.(단순히 득점 값이라고도 함). 그런 다음 2016 시즌 모든 타자의 평균 득점 값 분포를 탐색합니다. 호세 알투베 선수의 득점 값을 사용하여 선수 간의 의미를 구체화합니다. 이어서 선수들이 타순에 따라 어떻게 달라지는 지를 볼 것입니다. 기대 득점 값의 개념은 다양한 타격 플레이의 상대적 이점을 이해하는 데 유용하며, 홈런과 단타에 대해서도 알아볼 것입니다. 마지막으로, 득점 기대 행렬과 득점 값을 사용하여 도루의 이점과 도루 실패의 비용을 알아볼 것입니다.
이닝의 나머지 부분에서 기록된 득점
4장을 하면서 설치한 abdwr3edata 패키지에서 retro2016 데이터를 가져와줍니다.
library(abdwr3edata)
data("retro2016", package = "abdwr3edata")
특정 타석에서는 득점할 가능성이 존재합니다. 주자가 베이스에 있을 때, 특히 득점권(2루 또는 3루)에 있을 때와 아웃 수가 적을 때 이 득점 가능성은 확연히 커집니다. 이 득점 잠재력은 일정 기간 동안 베이스에 주자가 있는 조합과 아웃 수에 대해 이닝의 나머지 부분에서 평균 득점 수를 계산하여 추정합니다. 물론, 평균 득점 수는 홈팀 대 원정팀, 현재 점수, 투수, 수비 등 여러 변수에 따라 달라집니다. 그러나 이 득점 잠재력은 이닝 중 일반적인 상황에서 득점 기회를 나타내며, 선수들의 기여도를 측정하는 유용한 기준선이 됩니다.
이닝의 나머지 부분에서 득점 수를 계산하려면, 타석 동안 두 팀이 득점한 총점수와 특정 하프 이닝 종료 시 두 팀이 득점한 총점수를 알아야 합니다. 이닝의 나머지 부분에서 득점한 점수(runs_roi로 표시)는 이 두 값의 차이로 계산됩니다.
runsroi=runsTotalinInning−runsSofarinInning
mutate() 함수를 사용하여 여러 새로운 변수를 생성합니다. runs_before는 각 타석에서 원정팀 점수(away_score_ct)와 홈팀 점수(home_score_ct)의 함으로 정의되며, half_inning 변수는 paste() 함수를 사용하여 게임 ID, 이닝, 타격 팀을 결합하여 각 경기의 하프 이닝을 고유하게 식별할 수 있도록 합니다. 또한, 각 플레이에서 득점한 점수를 나타내는 runs_scored라는 새로운 변수를 생성합니다.(변수 bat_dest_id, run1_dest_id, run2_dest_id, run3_dest_id는 타자와 각 주자의 최종 목적지를 나타내며, 주자가 3루를 초과하여 도달한 베이스에 대해 득점이 기록됩니다.)
retro2016 <- retro2016 |>
mutate(
runs_before = away_score_ct + home_score_ct,
half_inning = paste(game_id, inn_ct, bat_home_id),
runs_scored =
(bat_dest_id > 3) + (run1_dest_id > 3) +
(run2_dest_id > 3) + (run3_dest_id > 3)
)
각 하프 이닝의 최대 총득점을 계산하고자 합니다. 이를 위해 홈팀과 원정팀의 점수를 합산합니다. half_inning으로 그룹화한 후 summarize() 함수를 사용하여 이 작업을 수행합니다. summarize() 함수 내에서 outs_inning은 각 하프 이닝의 아웃 수, runs_inning은 각 하프 이닝에서 기록된 총 득점, runs_start는 하프 이닝 시작 시의 점수, 그리고 max_runs는 하프 이닝에서의 최대 총 득점(초기 총득점과 득점한 점수의 합계)입니다. 이 요약 데이터는 새로운 데이터 프레임인 half_inning에 저장됩니다.
half_innings <- retro2016 |>
group_by(half_inning) |>
summarize(
outs_inning = sum(event_outs_ct),
runs_inning = sum(runs_scored),
runs_start = first(runs_before),
max_runs = runs_inning + runs_start
)
inner_join() 함수를 사용하여 data2016 데이터 프레임과 half_innings 데이터 프레임을 병합합니다. 그런 다음, 이닝의 나머지 부분에서 득점한 점수(runs_roi라는 새로운 변수)는 max_runs와 runs의 차이를 계산하여 구할 수 있습니다.
retro2016 <- retro2016 |>
inner_join(half_innings, by = "half_inning") |>
mutate(runs_roi = max_runs - runs_before)
행렬 생성
이제 각 타석에서 이닝의 나머지 부분에서 득점한 점수 변수가 계산되었으므로, 득점 기대 행렬을 계산하는 것은 간단합니다.
현재, 1루(base1_run_id), 2루(base2_run_id), 3루(base3_run_id)에 각각 주자가 있는 경우 해당 주자의 플레이어 코드가 포함된 세 가지 변수가 있습니다. 우리는 각 자리에 주자가 있는 경우 1, 없는 경우 0으로 표현한 새로운 세 자리 변수 bases를 생성합니다. state 변수는 이 변수에 아웃 수를 추가한 것입니다. state 변수의 한 예로 "011 2"는 현재 2루와 3루에 주자가 있고 두 개의 아웃이 있음을 나타냅니다. 또 다른 state 값이 "100 0"은 1루에 주자가 있고 아웃이 없는 상태를 나타냅니다.
retro2016 <- retro2016 |>
mutate(
bases = paste0(
if_else(base1_run_id == "", 0, 1),
if_else(base2_run_id == "", 0, 1),
if_else(base3_run_id == "", 0, 1)
),
state = paste(bases, outs_ct)
)
우리는 데이터 프레임에서 주자, 아웃 수 또는 득점에 변화가 있는 플레이만 고려하고자 합니다. 이를 위해 새로운 세 개의 변수 is_runner1, is_runner2, is_runner3을 생성합니다. 이 변수들은 각각 1루, 2루, 3루가 플레이 후에 점유되어 있는지를 나타냅니다. (as.numeric() 함수는 논리 변수를 숫자 변수로 변환합니다.)
new_outs 변수는 플레이 후의 아웃 수를, new_bases 변수는 점유된 베이스를,. new_state 변수는 각 베이스에 있는 주자와 플레이 후의 아웃 수를 나타냅니다.
retro2016 <- retro2016 |>
mutate(
is_runner1 = as.numeric(
run1_dest_id == 1 | bat_dest_id == 1
),
is_runner2 = as.numeric(
run1_dest_id == 2 | run2_dest_id == 2 |
bat_dest_id == 2
),
is_runner3 = as.numeric(
run1_dest_id == 3 | run2_dest_id == 3 |
run3_dest_id == 3 | bat_dest_id == 3
),
new_outs = outs_ct + event_outs_ct,
new_bases = paste0(is_runner1, is_runner2, is_runner3),
new_state = paste(new_bases, new_outs)
)
filter() 함수를 사용하여 state와 new_state 간에 변화가 있거나 플레이에서 득점이 발생한 경우로 관심 범위를 제한합니다.
changes2016 <- retro2016 |>
filter(state != new_state | runs_scored > 0)
득점 기대치를 계산하기 전에 최종 조정이 필요합니다. 플레이별 데이터베이스에는 2016 시즌 동안 모든 하프 이닝에 대한 득점 정보가 포함되어 있으며, 여기에는 승리하는 득점이 3 아웃 이전에 기록된 경기 종료 시의 부분적인 하프 이닝도 포함됩니다. 득점 기대치를 계산할 때, 우리는 3 아웃이 기록된 완전한 하프 이닝만을 고려하고자 합니다.
filter() 함수를 사용하여 changes2016 데이터 프레임에서 정확히 3아웃이 기록된 하프 이닝의 데이터를 추출합니다. 새로운 데이터 프레임은 chages2016_complete라고 명명됩니다.(불완전한 이닝을 제거함으로써, 우리는 적어도 하나의 득점으로 인해 이닝이 완전히 끝나지 않았기 때문에 약간의 편향을 도입하게 됩니다.)
changes2016_complete <- changes2016 |>
filter(outs_inning == 3)
24개의 베이스/아웃 상황 각각에 대해 이닝의 나머지 부분에서 득점할 것으로 예상되는 점수(득점 기대치)를 계산하기 위해 summarize() 함수를 사용합니다. 이는 베이스와 아웃 수(outs_ct)로 그룹화한 후, mean() 함수를 사용하여 평균을 구하는 방식으로 이루어집니다. 결과 데이터 프레임은 erm_2016으로 정의하고 저장합니다.
erm_2016 <- changes2016_complete |>
group_by(bases, outs_ct) |>
summarize(mean_run_value = mean(runs_roi))
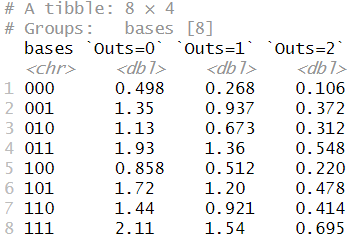
이 득점 값을 8 × 3 행렬로 표시하기 위해, pivot_wider() 함수를 사용합니다.
erm_2016 |>
pivot_wider(
names_from = outs_ct,
values_from = mean_run_value,
names_prefix = "Outs="
)
득점 기대치가 시잔이 지남에 따라 어떻게 변했는지 확인하기 위해, Albert와 Bennett(2003)에 보고된 2002 시즌 값을 erm_2002 행렬에 입력합니다. 2016년과 2002년의 득점 기대치를 비교하기 위해 bind_cols() 함수를 사용하여 나란히 표시해 줍니다.
erm_2002 <- tibble(
"OLD=0" = c(.51, 1.40, 1.14, 1.96, .90, 1.84, 1.51, 2.33),
"OLD=1" = c(.27, .94, .68, 1.36, .54, 1.18, .94, 1.51),
"OLD=2" = c(.10, .36, .32, .63, .23, .52, .45, .78)
)
out <- erm_2016 |>
pivot_wider(
names_from = outs_ct,
values_from = mean_run_value,
names_prefix = "NEW="
) |>
bind_cols(erm_2002)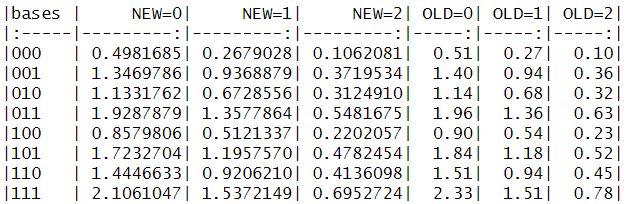
이 득점 기대치가 최근 야구 역사에서 크게 변하지 않았다는 것은 다소 놀라운 일입니다. 이는 2002년과 2016년 사이에 MLB 팀들의 평균 득점 경향에 큰 변화가 없었음을 나타냅니다.
타격 플레이의 성공 측정
특정 주자와 아웃 상황에서 타자가 타석에 들어설 때, 득점 기대 행렬은 해당 하프 이닝의 나머지 부분에서 팀이 득점할 평균 점수를 알려줍니다. 타석의 결과에 따라 주자 및 아웃 상황이 변경되며, 이에 따라 업데이트된 득점 기대치 값이 생성됩니다. 우리는 타격 결과를 구체적인 플레이에서 기록된 득점 수에 더한 이전 상태와 새로운 상태의 득점 기대치 차이를 계산하여 타석의 가치를 추정합니다.
RUN VALUE=RUNSNewstate−RUNSOld state+RUNSScored on Play
다음 R 코드를 사용하여 원본 데이터 프레임 retro2016의 모든 플레이에 대해 득점 가치를 계산합니다. 먼저, left_join() 함수를 사용하여 각 타석의 시작 시점에 예상되는 득점 값을 일치시킵니다. 이를 위해 retro2016의 bases 및 outs_ct 변수를 득점 기대 행렬 erm_2016의 해당 변수와 일치시킵니다.
이렇게 하면 mean_run_value라는 새로운 변수가 생성되며, 이를 즉시 rv_start로 이름을 변경합니다. 다음으로, new_bases 및 new_outs 변수를 득점 기대 행렬과 다시 일치시켜 rv_end 변수를 생성합니다. 여기서는 three out 상황이 erm_2016에 존재하지 않기 때문에 left_join()을 사용해야 합니다. three out 상황의 득점 기대치는 명백히 0이므로, replace_na() 함수를 사용하여 이러한 득점 값을 0으로 설정합니다.
따라서 retro2016 데이터셋에서 rv_start 변수는 현재 상태의 득점 기대치로 정의되고, rv_end 변수는 새로운 상태의 득점 기대치로 정의됩니다. 새로운 변수 run_value는 rv_end와 rv_start의 차이에 runs_scored를 더한 값으로 설정됩니다.
retro2016 <- retro2016 |>
left_join(erm_2016, join_by("bases", "outs_ct")) |>
rename(rv_start = mean_run_value) |>
left_join(
erm_2016,
join_by(new_bases == bases, new_outs == outs_ct)
) |>
rename(rv_end = mean_run_value) |>
replace_na(list(rv_end = 0)) |>
mutate(run_value = rv_end - rv_start + runs_scored)
호세 알투베
득점 가치를 더 잘 이해하기 위해, 2016 시즌 동안 위대한 타자 호세 알투베의 타석에 집중해 봅시다. 알투베의 player ID를 찾기 위해, Lahman 패키지의 People 데이터 프레임을 사용하고 filter() 함수를 사용하여 retroID를 추출합니다. pull 함수는 데이터 프레임에서 retroID 벡터를 추출합니다.
library(Lahman)
altuve_id <- People |>
filter(nameFirst == "Jose", nameLast == "Altuve") |>
pull(retroID)
그다음, filter() 함수를 사용하여 알투베의 타석 데이터 프레임인 altuve를 추출합니다. 여기서 타자 ID(변수 bat_id)는 altuve_id와 동일합니다. 알투베가 타자로 나선 타격 플레이만 고려하기 위해, 타격 플래그(변수 bat_event_fl)가 true인 행도 선택합니다.
altuve <- retro2016 |>
filter(
bat_id == altuve_id,
bat_event_fl == TRUE
)
알투베가 해당 시즌 첫 세 타석에서 어떻게 활약했는지 알아봅시다. 이를 위해 데이터 프레임 altuve의 처음 세 행을 표시하여 원래 상태, 새로운 상태, 그리고 득점 가치(run value) 변수를 확인합니다:
altuve |>
select(state, new_state, run_value) |>
slice_head(n = 3)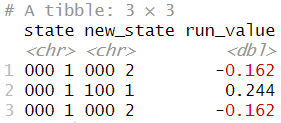
알투베의 첫 번째 타석에서는 1 아웃에 주자가 없었습니다. 이 타석의 결과는 2아웃에 주자가 없는 상태로, 이는 알투베가 아웃되었음을 나타냅니다. 이 플레이의 득점 가치는 -0.162점이었습니다. 두 번째 타석에서도 1아웃에 주자가 없었으며, 이번에는 알투베가 출루하였고 "000 1"에서 "100 1"로 상태가 전환되어 득점 가치는 0.244점이었습니다. 세 번째 타석에서도 알투베는 주자가 없는 1아웃 상황에서 아웃되었으며, 이 타석의 득점 가치는 -0.162점이었습니다.
어떤 선수의 득점 가치를 평가할 때 두 가지 주요 질문이 있습니다. 첫째, 선수의 득점 기회를 이해할 필요가 있습니다. 선수의 타석에서 주자/아웃 상황은 어땠습니까? 둘째, 타자는 이러한 득점 기회에서 무엇을 했습니까? 타자의 성공 또는 실패는 이러한 득점 가치와 관련하여 측정될 수 있습니다.
알투베의 득점 기회를 이해하기 위해 주자 상태에 집중해 봅시다. 32번의 결과 중 일부 주자/아웃 상태의 카운트가 거의 0에 가까운 것을 감안하여, 주자가 있는 베이스 변수를 중심으로 살펴보겠습니다. summarize() 함수 내에서 n() 함수를 적용하여 알투베의 모든 타석에 대한 주자 상태를 집계합니다.
altuve |>
group_by(bases) |>
summarize(N = n())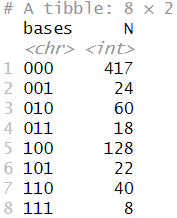
우리는 알투베가 일반적으로 주자가 없는 상황(000)이나 1루에만 주자가 있는 상황(100)에서 타석에 들어섰음을 알 수 있습니다. 대부분의 경우, 알투베는 득점권에 주자가 없는 상태에서 타격을 했습니다.
이러한 기회에서 알투베는 어떻게 활약했을까요? geom_jitter() 기하 객체를 사용하여, 주자 상태별로 모든 타석의 득점 가치를 보여주는 지터된 산점도를 작성합니다. 수평 방향으로 점들을 지터링하는 것은 득점 가치의 밀도를 나타내는 데 도움이 됩니다. 또한 그래프에 수평선(값 0)을 추가하여, 선 위의 점들은 긍정적인 기여(positive contributions)를, 선 아래의 점들은 부정적인 기여(negative contributions)를 나타내도록 합니다.
ggplot(altuve, aes(bases, run_value)) +
geom_jitter(width = 0.25, alpha = 0.5) +
geom_hline(yintercept = 0, color = "red") +
xlab("Runners on base")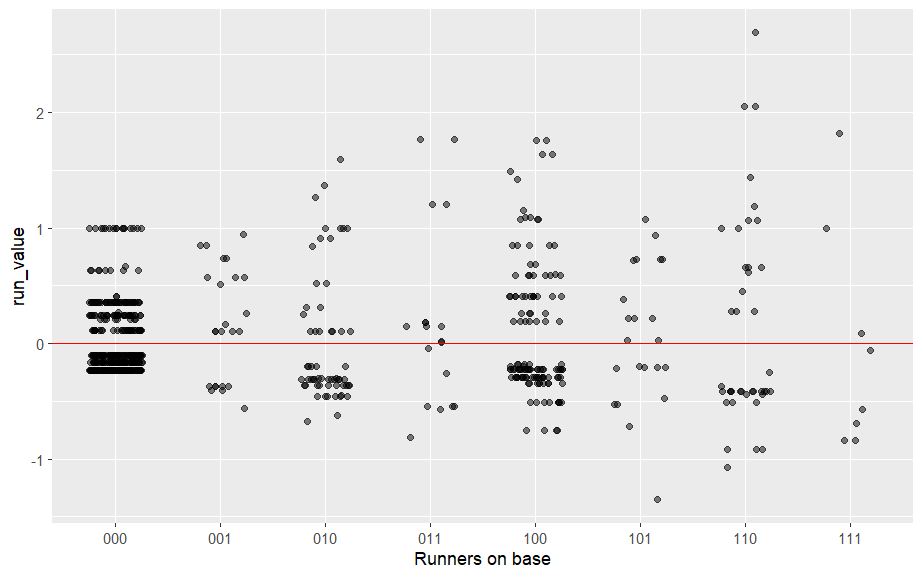
주자가 없는 상황(000)에서는 가능한 득점 가치의 범위가 상대적으로 작았습니다. 이 상태에서, 음수 득점 가치에 있는 큰 점군(cluster)은 알투베가 주자가 없는 상황에서 아웃된 많은 경우를 나타냅니다. 값이 1인 (000) 지점의 점군은 알투베가 주자가 없는 상태에서 홈런을 친 경우를 나타냅니다. (주자가 없는 상황에서의 홈런은 베이스/아웃 상태를 변경하지 않으며, 이 플레이의 가치는 정확히 1점입니다.)
다른 상황, 예를 들어 만루 상황(111)에서는 득점 가치의 변동이 훨씬 큽니다. 한 타석에서는 상태가 111 1에서 111 2로 바뀌었는데, 이는 알투베가 만루 상황에서 아웃된 경우를 나타내며, 이 경우의 득점 가치는-0.84입니다. 반대로, 알투베가 1 아웃에 만루 상황에서 2루타를 친 경우도 있었으며, 이 결과의 득점 가치는 1.82였습니다.
알투베의 2016 시즌 총 득점 생산량을 이해하기 위해, summarize() 함수와 sum() 및 n() 함수를 함께 사용하여 각 주자 상황에 대한 기회 수와 득점 가치의 합계를 계산합니다.
runs_altuve <- altuve |>
group_by(bases) |>
summarize(
PA = n(),
total_run_values = sum(run_value)
)
runs_altuve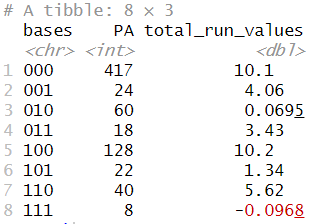
예를 들어, 알투베는 417번 주자가 없는 상황에서 타석에 들어섰으며, 이 417번의 타석에서 그의 총 득점 기여도는 10.10점이었습니다. 알투베는 득점권에 주자가 있는 상황에서 특별히 잘하지 못한 것처럼 보입니다. 예를 들어, 2루에 주자가 있는 상황에서 60번의 타석이 있었고, 이 상황에서 그의 순 득점 기여도는 0.07점이었습니다.
2016 시즌 동안 알투베의 총 득점 기여도는 이 데이터 프레임의 마지막 열을 합산하여 계산할 수 있습니다. 이 타격 성과 측정 지표는 24개의 베이스/아웃 상태에서 득점 기대치의 변화를 나타내기 때문에 RE24로 알려져 있습니다(Appelman 2008).
runs_altuve |>
summarize(RE24 = sum(total_run_values))
알투베가 2016 시즌 동안 타석에서 긍정적인 총기여도를 기록한 것은 놀랍지 않지만, 이 기여도의 크기인 34.7점이 다른 선수들과 비교되지 않으면 이해하기 어렵습니다. 다음번에는 2016 시즌의 모든 타자들과 Altuve를 비교해 보겠습니다.
'야구 분석 > R' 카테고리의 다른 글
| 포수 프레이밍이란? (0) | 2024.08.14 |
|---|---|
| 안타와 도루의 가치 (0) | 2024.08.10 |
| 메이저리그 타자들의 득점 기대치 (0) | 2024.08.08 |
| 피타고리안 승률을 이용해보기 (0) | 2024.07.30 |
| 야구에서 득점과 승리의 관계 (0) | 2024.07.15 |