주제
Analyzing Baseball Data with R (3e)을 이용해서 R로 야구 데이터를 분석하는 것을 알아볼 것입니다. 책의 내용 중 4장 The Relation Between Runs and Wins를 따라 하며 야구 분석에 대해 배우고자 합니다.
야구팀의 목표는 다른 스포츠의 팀들과 마찬가지로 경기를 이기는 것입니다. 마찬가지로, 야구 분석가의 목표는 경기장에서 일어나는 일을 승리의 측면에서 측정할 수 있는 능력을 갖추는 것입니다.
승리는 상대팀보다 더 많은 득점을 함으로써 얻어지며, 따라서 한 시즌 동안 팀이 얻는 승리의 비율은 득점과 허용하는 점수의 수와 강한 상관관계를 가집니다. 이번에는 득점과 승리 사이의 관계를 탐구해 보겠습니다.
Lahman 데이터베이스의 Teams 테이블
library(Lahman)
Teams |>
slice_tail(n = 3)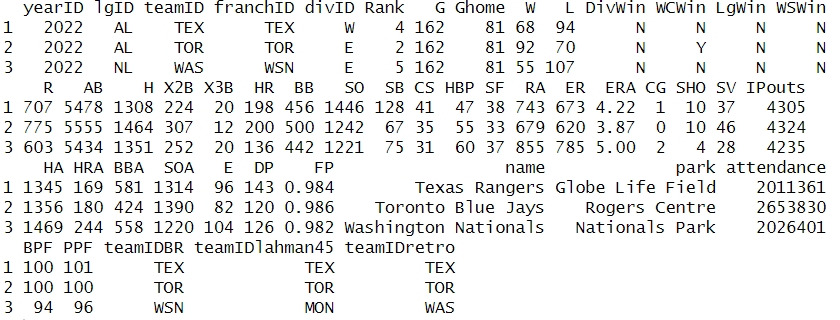
Lahman 패키지의 Teams 테이블은 1871년 첫 프로 시즌부터 시작하여 메이저 리그 팀의 시즌 통계를 포함하고 있습니다. 먼저, 이 데이터를 R에 로드하고 slice_tail() 함수를 사용해 데이터셋의 마지막 부분을 살펴보겠습니다.
my_teams <- Teams |>
filter(yearID > 2000) |>
select(teamID, yearID, lgID, G, W, L, R, RA)
my_teams |>
slice_tail(n = 6)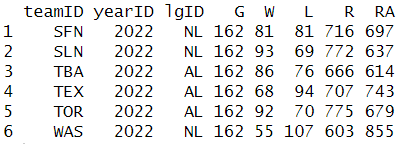
팀의 승리 비율을 득점 및 실점과 연관시키고자 한다면, 이 테이블에서 관심 가져야 할 관련 필드는 경기 수(G), 팀 승리 수(W), 패배 수(L), 총 득점 수(R), 총 허용 점수(RA)입니다.
팀 정보(teamID), 시즌(yearID), 리그(lgID)와 함께 위의 다섯 개 열만 포함시키는 새로운 데이터 프레임을 생성하겠습니다. 최근 시즌에서 승리와 득점 사이의 관계를 알아보고자 하므로 2001년 이후의 시즌에 초첨을 맞추겠습니다.
my_teams <- my_teams |>
mutate(RD = R - RA, Wpct = W / (W + L))
득실점 차이(Run Differential)는 팀이 득점한 점수와 실점한 점수의 차이로 정의됩니다. 승률은 팀이 승리한 경기의 비율입니다. 야구에서는 승률(Winning Percentage)을 사용하는데 득실점 차이와 승률을 계산해 주겠습니다.
run_diff <- ggplot(my_teams, aes(x = RD, y = Wpct)) +
geom_point() +
scale_x_continuous("Run differential") +
scale_y_continuous("Winning percentage")
득실점 차이와 승률의 관계를 파악하기 위해 두 변수의 산점도를 그려줍니다. 이후에 이 그래프에 추가 작업을 할 예정이므로, 그래프를 보여주는 것은 뒤로 미루겠습니다.
선형 회귀
팀의 승률을 득점과 실점을 사용하여 예측하는 한 가지 간단한 방법은 선형 회귀를 사용하는 것입니다. 간단한 선형 모델은 다음과 같이 표현됩니다.
$$Wpct = a+b \times RD+\epsilon ,$$
여기서 α 와 β 는 미지의 상수이고, ϵ 는 응답 변수(Wpct)에 영향을 미치는 다른 모든 요인을 포함하는 오차 항입니다. 이는 stats 패키지(기본적으로 R에 설치되고 로드됨)의 lm() 함수를 사용하여 피팅되는 선형 모델의 특수한 경우입니다.
linfit <- lm(Wpct ~ RD, data = my_teams)
linfit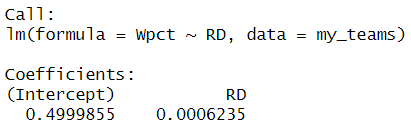
이 함수에 대한 가장 기본적인 호출은 response ~ predictor1 + predictor2 +... 형태의 공식과 data = dataset 인수를 필요로 합니다. 여기서 모델링할 변수(종속 변수)는 물결표(~) 문자 왼쪽에, 예측 변수는 오른쪽에 지정됩니다. 다음 lm() 함수의 예에서는 data 인수를 사용하여 사용할 데이터 프레임을 지정합니다.
run_diff +
geom_smooth(method = "lm", se = FALSE, color = "#1f78b4")
코드를 실행하면 위의 그림과 같이 산점도가 표시되며, 이는 강한 양의 상관관계를 보여줍니다. 득실점 차가 큰 팀은 승리할 가능성이 더 큰 것을 알 수 있습니다.
2001년부터 2023년까지 메이저 리그 팀의 득실점 차와 팀 승률에 대한 산점도를 확인했고 팀의 예상 승률은 득실점차로부터 다음 방정식을 사용하여 추정할 수 있습니다.
$$\widehat{Wpct}=0.499985+0.000624\times RD$$
이 공식은 득실점차(RD = 0)가 0인 팀이 절반의 경기를 승리할 것임을 알려줍니다(추정 절편 ≈ 0.500) - 이는 바람직한 특성입니다. 또한, 득실점차가 1 단위 증가하면 승률이 0.000624 증가합니다.
예를 들어, 750점을 득점하고 750점을 허용한 팀은 일반적인 MLB 시즌 162경기에서 절반인 81경기를 승리할 것으로 예측됩니다. 반면, 760점을 득점하고 750점을 허용한 팀은 득실점차가 +10이며, 승률은 0.500 + 10 × 0.000624 ≈ 0.506으로 예측됩니다. 162경기 일정에서 승률 0.506은 82승에 해당합니다. 따라서 득실점차가 10점 증가하면, 직선형 모델에 따르면 팀 순위에서 예상되는 승리 수가 추가로 1승 증가합니다.
이 모델에 대한 한 가지 우려는 피팅된 선의 예측이 [0, 1] 범위를 벗어날 수 있다는 점입니다. 예를 들어, 상대를 총 805점 차이로 이기는 가상의 팀은 모든 경기에서 100% 이상 승리할 것으로 예측되는데, 이는 불가능합니다. 그러나 메이저 리그 야구 역사상 팀의 득실점차가 -350에서 +350 사이인 경우가 99% 이상이기 때문에, 직선형 모델은 합리적입니다.
library(broom)
my_teams_aug <- augment(linfit, data = my_teams)
모델이 피팅된 후, broom 패키지의 augment() 함수를 사용하여 모델에서 예측 값을 계산하고 잔차를 구합니다. 잔차는 응답 값과 피팅된 값(즉, 실제 승률과 추정된 승률) 사이의 차이를 측정합니다.
base_plot <- ggplot(my_teams_aug, aes(x = RD, y = .resid)) +
geom_point(alpha = 0.3) +
geom_hline(yintercept = 0, linetype = 3) +
xlab("Run differential") + ylab("Residual")
highlight_teams <- my_teams_aug |>
arrange(desc(abs(.resid))) |>
slice_head(n = 4)
library(ggrepel)
base_plot +
geom_point(data = highlight_teams, color = crcblue) +
geom_text_repel(
data = highlight_teams, color = crcblue,
aes(label = paste(teamID, yearID))
)
위의 그림은 피팅된 선형 모델의 득실점차에 대한 잔차를 나타냅니다. 잔차가 큰 4 팀을 라벨링해주었습니다.
잔차는 실제 승률을 예측하는 선형 모델의 오류로 해석될 수 있습니다. 따라서 위의 그림에서 0 선에서 가장 먼 점들은 선형 모델이 승률을 예측하는 데 가장 부진한 성과를 보인 팀들을 나타냅니다.
잔차 그래프에서 상위에 있는 극값은 중 하나는 2008년 LA에인절스를 나타냅니다. 그들의 +68 득실점차를 고려할 때. 선형 방정식에 따르면 0.542의 승률을 가져야 했습니다. 그러나 그들은 시즌을 0617로 마쳤습니다. 이 팀의 잔차 값은 0.617 - 0.542 = 0.075, 또는 0.075 x 162 = 12.2 경기에 해당합니다. 다른 한편으로, 2006년 클리블랜드 인디언스는 +88 득실점차로 선형 모델에 의해 0.555 팀으로 간주되었지만, 실제로는 0.481로 마쳤으며, 이는 잔차 0.481 - 0.555 = -0.073, 또는 -11.8 경기에 해당합니다.
최소제곱 선형 모델의 잔차의 평균 값은 0과 같으며, 이는 모델 예측이 승률을 과대평가하거나 과소평가할 가능성이 동일함을 의미합니다. 통계적으로, 우리는 모델을 피팅하는 방법이 편향되지 않았다고 말합니다. 오류의 평균 크기를 추정하기 위해, 먼저 잔차를 제곱하여 각 오류가 양수 값을 갖도록 하고, 제곱된 잔차의 평균을 계산한 다음, 각 평균값을 원래 규모로 되돌리기 위해 제곱근을 취합니다. 이렇게 계산된 값을 루트 평균 제곱오차(RSME)라고 합니다.
resid_summary <- my_teams_aug |>
summarize(
N = n(),
avg = mean(.resid),
RMSE = sqrt(mean(.resid^2))
)
resid_summary
rmse <- resid_summary |>
pull(RMSE)
오류가 정규 분포를 따른다면, 잔차의 약 2/3는 -RSME와 +RSME 사이에 위치하며, 잔차의 95%는 -2 * RMSE와 2 * RMSE 사이에 위치합니다. 이러한 명제는 다음 코드 라인으로 확인할 수 있습니다. (abs() 함수는 절대값을 계산합니다.)
my_teams_aug |>
summarize(
N = n(),
within_one = sum(abs(.resid) < rmse),
within_two = sum(abs(.resid) < 2 * rmse)
) |>
mutate(
within_one_pct = within_one / N,
within_two_pct = within_two / N
)
함수 n()을 summarize() 함수와 함께 사용하여 데이터 프레임의 행 수를 구합니다. 표현식의 분자에서는 잔차(abs() 함수를 사용하여 계산)를 구하고, 이 잔차가 하나의 RMSE와 두 개의 RMSE보다 작은 수를 구합니다. 계산된 비율은 위에서 언급한 이론적 값인 68%와 95%에 근접합니다.
'야구 분석 > R' 카테고리의 다른 글
| 포수 프레이밍이란? (0) | 2024.08.14 |
|---|---|
| 안타와 도루의 가치 (0) | 2024.08.10 |
| 메이저리그 타자들의 득점 기대치 (0) | 2024.08.08 |
| 득점 기대치를 사용한 플레이 가치를 평가해보기 (1) | 2024.08.03 |
| 피타고리안 승률을 이용해보기 (0) | 2024.07.30 |