주제
이 번에서는 2022 시즌의 Statcast 데이터를 사용하여 포수의 프레이밍 능력에 대해 알아보겠습니다.
야구 분석에서 포수의 프레이밍 능력 이야기는 흥미롭습니다. 역사적으로 스카우트와 코치들은 특정 포수들이 심판을 위해 투구를 '프레임'하는 능력을 가지고 있다고 주장했습니다. 이는 글러브를 상대적으로 고정시켜 심판을 속여서 스트라이크 존 밖에 있는 투구도 스트라이크로 판정받게 할 수 있다는 아이디어입니다(Lindbergh(2013)의 훌륭한 시각적 설명 참조). 야구 분석가들은 이 능력의 존재와 영향에 대해 대체로 회의적이었습니다. 포수의 수비 능력의 영향을 연구한 대부분의 사람들은 스카우트와 코치들이 믿는 것만큼 가치가 크지 않다고 결론지었습니다.
문제의 일부는 2000년대 중반까지 투구 수준의 데이터를 구하기 어려웠다는 점이었습니다. PITCHf/x의 출현으로 이러한 더 세분화된 데이터에 대해 더 정교한 모델링 기술이 가능해졌습니다. 포수 프레이밍의 영향을 추정하는 새로운 연구들은 지속적인 능력의 존재(즉, 좋은 프레이밍 수치를 가진 포수들은 시간이 지나도 계속 좋았다)와 그 효과의 크기(즉, 좋은 프레이머들은 실제로 매우 가치 있었다)를 입증했습니다(Turkenkopf 2008; Fast 2011; Brooks and Pavlidis 2014; Brooks, Pavilidis, and Judge 2015; Deshpande and Wyner 2017; Judge 2018).
이러한 새로운 발견들은 야구 산업에 변화를 가져왔습니다. 호세 몰리나 같은 수비 중심의 포수들은 타격 실력으로는 정당화될 수 없는 다년 계약을 받기 시작했습니다. 마이너 리그 교육에서는 프레이밍 기술 향상에 더 큰 비중을 두게 되었습니다. 물론 MLB가 로봇이 볼과 스트라이크를 판정하도록 결정하는 순간, 이 포수 프레이밍 능력은 즉시 사라질 것입니다.
피치 리벨 데이터 획득
mutate() 및 case_match() 함수들을 사용하여, description 변수를 세 가지 카테고리인 "ball", "swinging_strike" 및 "called_strike"로 다시 코딩하는 Outcome 변수를 정의합니다. 또한, 홈 팀이 타석에 있는지 여부를 나타내는 Home 변수를 정의하고, 볼과 스트라이크의 수를 나타내는 Count 변수를 정의합니다.
sc2022 <- here::here("data_large/statcast_rds/statcast_2022.rds") |>
read_rds()
sc2022 <- sc2022 |>
mutate(
Outcome = case_match(
description,
c("ball", "blocked_ball", "pitchout",
"hit_by_pitch") ~ "ball",
c("swinging_strike", "swinging_strike_blocked",
"foul", "foul_bunt", "foul_tip",
"hit_into_play", "missed_bunt" ) ~ "swing",
"called_strike" ~ "called_strike"),
Home = ifelse(inning_topbot == "Bot", 1, 0),
Count = paste(balls, strikes, sep = "-")
)
filter() 함수를 사용하여, 타자가 스윙하지 않은 투구들만 포함된 taken 데이터 프레임을 구성합니다. 따라서 이 데이터 프레임에는 볼과 선언된 스트라이크만 포함됩니다. select() 함수를 사용하여 이 데이터셋에서 관심 있는 변수들을 선택하고, write_rds() 함수를 사용하여 taken 데이터 프레임을 압축된 형식으로 파일 sc_taken_2022.rds에 저장합니다.
taken <- sc2022 |>
filter(Outcome != "swing")
taken_select <- select(
taken, pitch_type, release_speed,
description, stand, p_throws, Outcome,
plate_x, plate_z, fielder_2_1,
pitcher, batter, Count, Home, zone
)
write_rds(
taken_select,
here::here("data/sc_taken_2022.rds"),
compress = "xz"
)
일단 이 데이터가 저장되면, read_rds() 함수를 사용하여 R로 데이터를 읽어올 수 있습니다. 우리는 sample_n() 함수를 사용하여 이 데이터셋에서 무작위로 추출한 50,000개의 행을 사용하여 분석을 진행합니다.
스트라이크 존은 어디일까?
포수 프레이밍의 영향을 이해하기 위해서는 주어진 투구가 스트라이크로 판정될 확률을 특징짓는 방법이 필요합니다. Statcast 데이터에서 각 투구는 Outcome 변수로, 선언된 스트라이크의 경우 called_strike, 볼의 경우 ball로 표시됩니다. 우리는 이 결과들을 그림 1에 표시합니다. 스트라이크 존에 던져진 투구는 스트라이크로 판정되는 경향이 있음을 알 수 있습니다. 또한, 기술적으로 스트라이크 존 밖에 있음에도 불구하고 스트라이크로 판정되는 투구가 많다는 것도 주목할 필요가 있습니다.
plate_width <- 17 + 2 * (9/pi)
k_zone_plot <- ggplot(
NULL, aes(x = plate_x, y = plate_z)
) +
geom_rect(
xmin = -(plate_width/2)/12,
xmax = (plate_width/2)/12,
ymin = 1.5,
ymax = 3.6, color = crcblue, alpha = 0
) +
coord_equal() +
scale_x_continuous(
"Horizontal location (ft.)",
limits = c(-2, 2)
) +
scale_y_continuous(
"Vertical location (ft.)",
limits = c(0, 5)
)
스트라이크 존의 위치를 어떻게 아는가? 규칙에 따르면, 투구가 스트라이크로 판정되기 위해서는 공의 일부분이 홈 플레이트를 통과하기만 하면 됩니다. 홈 플레이트는 17인치(약 1.42피트) 너비이며, 공의 둘레는 9인치(약 0.75피트)입니다. 따라서 우리의 관점에서 스트라이크 존의 바깥쪽 경계는 약 0.947피트입니다. 스트라이크 존의 상단과 하단은 타자에 따라 다르지만, 여기서는 비교적 덜 중요합니다.
k_zone_plot 객체는 ggplot2의 빈 객체로, 그림 1에서 Statcast 데이터의 2000개의 행을 무작위로 샘플링하여 이 객체에 표시합니다.
k_zone_plot %+%
sample_n(taken, size = 2000) +
aes(color = Outcome) +
geom_point(alpha = 0.2) +
scale_color_manual(values = crc_fc)
스트라이크 존에 대해 생각하는 또 다른 방법은 Statcast에서 미리 정의된 구역을 사용하는 것입니다. 스트라이크 존 자체는 격자로 나누어져 있으며, 스트라이크 존 외부에도 네 개의 추가 영역이 정의됩니다. 먼저, 각 구역에서 선언된 스트라이크의 관찰 확률과 그 경계를 계산합니다. 이를 위해 quantile() 함수를 사용하여 이상치의 영향을 줄입니다.
zones <- taken |>
group_by(zone) |>
summarize(
N = n(),
right_edge = min(1.5, max(plate_x)),
left_edge = max(-1.5, min(plate_x)),
top_edge = min(5, quantile(plate_z, 0.95, na.rm = TRUE)),
bottom_edge = max(0, quantile(plate_z, 0.05, na.rm = TRUE)),
strike_pct = sum(Outcome == "called_strike") / n(),
plate_x = mean(plate_x),
plate_z = mean(plate_z)
)
그림 2에서는 각 구역과 해당 구역에서 투구가 스트라이크로 판정될 확률을 함께 표시합니다. 이 미리 정의된 구역들은 "on the black" (스트라이크 존의 경계에 걸쳐있는 투구들)을 제외하고 있습니다.
library(ggrepel)
k_zone_plot %+% zones +
geom_rect(
aes(
xmax = right_edge, xmin = left_edge,
ymax = top_edge, ymin = bottom_edge,
fill = strike_pct, alpha = strike_pct
),
color = "lightgray"
) +
geom_text_repel(
size = 3,
aes(
label = round(strike_pct, 2),
color = strike_pct < 0.5
)
) +
scale_fill_gradient(low = "gray70", high = crcblue) +
scale_color_manual(values = crc_fc) +
guides(color = FALSE, alpha = FALSE)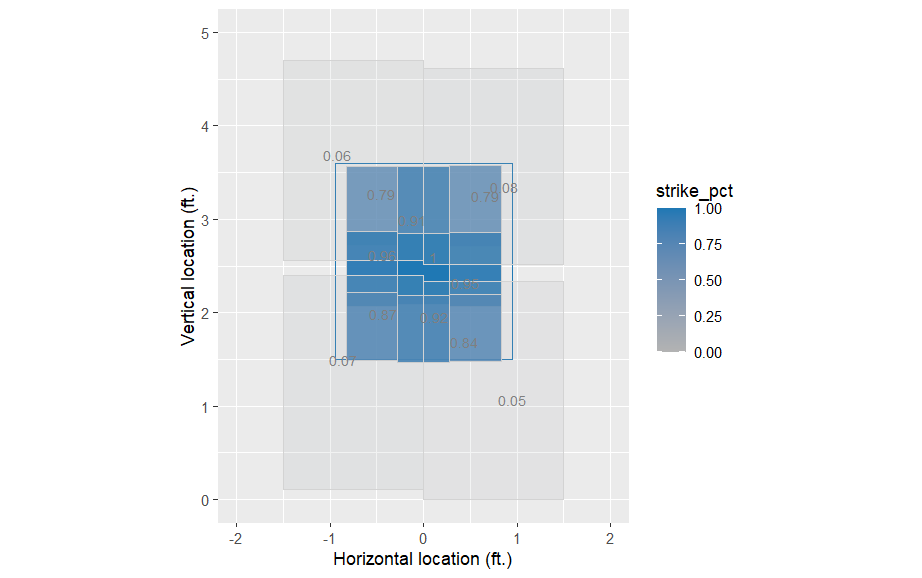
선언된 스트라이크 비율 모델링
그림 2의 구역 기반 스트라이크 확률은 그 이산적인 특성에 의해 제한됩니다. 우리가 정말로 원하는 것은 투구의 가로 및 세로 위치를 기반으로 모든 투구에 대한 예상 스트라이크 확률을 제공하는 모델입니다. 이를 위해 일반화 가법 모델(Generalized Additive Model, GAM)을 적합합니다.
이 모델은 전체 영역에 걸쳐 매끄러운 표면을 맞추면서, 위치에 대한 두 설명 변수만 포함합니다. mgcv 패키지의 s() 함수는 매끄러움이 적용될 변수를 나타내며, 여기서는 plate_x와 plate_z입니다. family 인수를 binomial로 설정하여, 우리의 이진 반응 변수(Outcome == "called_strike")를 모델링하기 위해 적절한 링크 함수(이 경우 로지스틱 함수)가 사용되도록 합니다.
library(mgcv)
strike_mod <- gam(
Outcome == "called_strike" ~ s(plate_x, plate_z),
family = binomial,
data = taken
)
예측값 시각화
모델이 생성한 예측값을 시각화하는 쉬운 방법은 적합된 값을 플로팅 하는 것입니다. 여기서는 broom 패키지의 augment() 함수를 사용하여 이러한 적합된 값을 계산하고 데이터 프레임에 추가합니다. type.predict 인수는 R에게 확률 척도(즉, 반응 변수)의 예측값을 계산하도록 지시합니다.
library(broom)
hats <- strike_mod |>
augment(type.predict = "response")다음으로, k_zone_plot 객체를 이 새로운 데이터 프레임으로 업데이트하고, 포인트(geom_point())를 추가하며, 방금 계산한 적합된 값(. fitted)에 색상 미학을 매핑할 수 있습니다. 그림 3은 이 데이터에서 GAM이 볼과 스트라이크의 패턴을 효과적으로 매핑했음을 보여줍니다.
k_zone_plot %+% sample_n(hats, 10000) +
geom_point(aes(color = .fitted), alpha = 0.1) +
scale_color_gradient(low = "gray70", high = crcblue)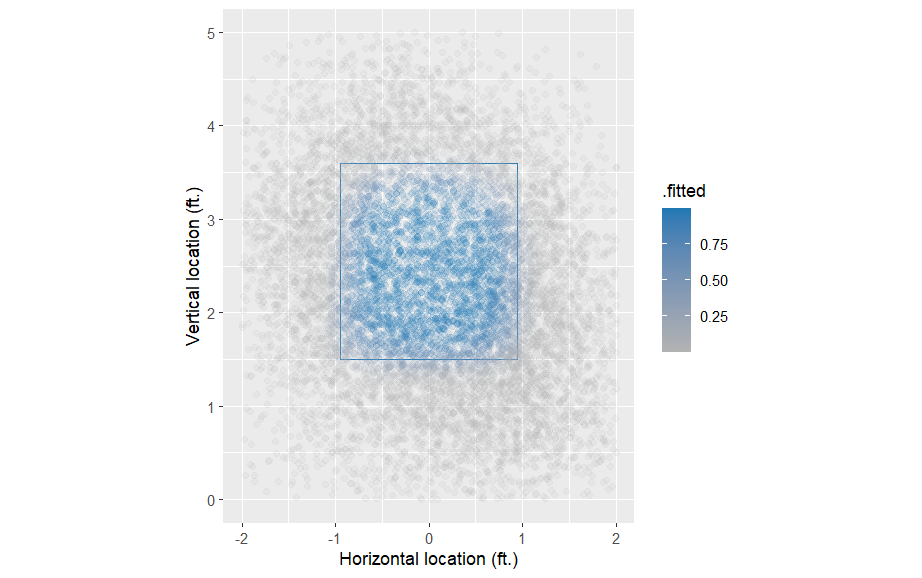
예상 표면 시각화
우리가 구축한 일반화 가법 모델(GAM)은 연속적인 표면입니다. 이러한 모델을 처음에 적합하는 이점 중 하나는, 훈련 데이터 세트에 있는 투구뿐만 아니라 위치 좌표를 아는 모든 투구에 대해 선언된 스트라이크 확률을 추정할 수 있다는 것입니다.
모델을 표면으로 시각화하려면 수평 및 수직 좌표 쌍의 세밀한 그리드 전체에 걸쳐 예상 확률을 플로팅 하면 됩니다. modelr 패키지에는 data_grid()와 seq_range()를 포함한 여러 함수가 있어 데이터에 관련된 값을 그리드로 만드는 데 도움을 줍니다.
library(modelr)
grid <- taken |>
data_grid(
plate_x = seq_range(plate_x, n = 100),
plate_z = seq_range(plate_z, n = 100)
)
그다음, 앞서했던 것처럼 augment() 함수를 사용하지만, 이번에는 newdata 인수를 우리가 방금 생성한 그리드 포인트의 데이터 프레임으로 지정합니다. 이로 인해 각 좌표 쌍에 대한 예상 선언된 스트라이크 확률이 포함된 10,000행의 데이터 프레임이 생성됩니다.
grid_hats <- strike_mod |>
augment(type.predict = "response", newdata = grid)
다시 한번, 이 새로운 데이터를 사용하여 k_zone_plot을 업데이트합니다. 그림 4에서 geom_tile() 함수는 geom_contour()에 대한 좋은 대안을 제공합니다.
tile_plot <- k_zone_plot %+% grid_hats +
geom_tile(aes(fill = .fitted), alpha = 0.7) +
scale_fill_gradient(low = "gray92", high = crcblue)
tile_plot
타격 방향 조정
규칙서와는 달리, 효과적인 스트라이크 존은 투수가 어느 손으로 던지느냐와 타자가 타석의 어느 쪽에 서 있느냐에 따라 달라질 수 있습니다.
결과적으로 생성된 데이터 프레임에는 plate_x와 plate_z로 인코딩 된 위치 데이터 외에도 p_throws와 stand 변수도 포함됩니다. 이제 이 네 가지 변수를 사용하여 또 다른 GAM을 적합할 수 있습니다. 이진 변수인 p_throws와 stand는 매끄럽게 처리되지 않으며, 따라서 모델 명세 공식에서 s() 함수의 외부에 위치합니다.
hand_mod <- gam(
Outcome == "called_strike" ~
p_throws + stand + s(plate_x, plate_z),
family = binomial,
data = taken
)
이제 두 개의 추가적인 이진 변수를 포함하도록 값의 그리드를 다시 계산해야 합니다.
hand_grid <- taken |>
data_grid(
plate_x = seq_range(plate_x, n = 100),
plate_z = seq_range(plate_z, n = 100),
p_throws,
stand
)
hand_grid_hats <- hand_mod |>
augment(type.predict = "response", newdata = hand_grid)
다음 코드는 타자와 투수의 타격 방향 조합 네 가지에 걸쳐 나누어 그린 플롯을 생성합니다. 그러나 이 네 개의 패싯(facet) 간의 뚜렷한 차이를 인지하기 어렵기 때문에, 여기서는 해당 플롯을 생략합니다.
tile_plot %+% hand_grid_hats +
facet_grid(p_throws ~ stand)
대신, 그림 5에서는 타격 방향 조합 네 가지 간의 표준 편차를 플롯 합니다. 스트라이크 존의 중심부에서는 타격 방향에 따른 차이가 나타나지 않습니다. 그러나 스트라이크 존 주변의 일부 영역에서는 선언된 스트라이크 확률의 표준 편차가 최대 2 퍼센트 포인트까지 나타납니다.
diffs <- hand_grid_hats |>
group_by(plate_x, plate_z) |>
summarize(
N = n(),
.fitted = sd(.fitted),
.groups = "drop"
)
tile_plot %+% diffs
다음번에는 포수 프레이밍 능력을 모델링하여 각 투구 시 포수가 스트라이크 판정 확률에 미치는 영향을 평가해 보겠습니다.
'야구 분석 > R' 카테고리의 다른 글
| 메이저리그 선수들의 커리어 살펴보기 (2) | 2024.09.08 |
|---|---|
| 미키 맨틀의 커리어 살펴보기 (0) | 2024.08.22 |
| 안타와 도루의 가치 (0) | 2024.08.10 |
| 메이저리그 타자들의 득점 기대치 (0) | 2024.08.08 |
| 득점 기대치를 사용한 플레이 가치를 평가해보기 (1) | 2024.08.03 |