24시즌 타자 기록 분석
시각화 주제KBO가 개막한 지 한 달 정도가 지나고 다양한 기록들이 나왔습니다. 하루에 홈런을 세 방 친 선수도 있고, 9타석 연속 안타를 친 선수도 있었습니다. 각 팀당 30경기 정도를 했고 물론
bbdiary03.tistory.com
저번에 이어서 24시즌 타자들의 기록을 분석하고 그 중 삼성라이온즈의 선수들의 기록을 확인해보겠습니다.
데이터를 불러와 타수와 OPS에 대한 값들을 히스토그램으로 확인을 해 보았었습니다. 이번에는 상관관계를 확인해 보고 삼성 선수들의 데이터를 확인해보겠습니다.
상관관계 확인하기
타자의 지표를 볼 수 있는 타수, 안타, 홈런, 득점, 타점, 볼넷, 삼진으로 상관관계를 확인해보겠습니다. 3가지 방법으로 확인 해 보았습니다.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 열 인덱스가 0부터 시작하므로 2에서 8까지의 열에 새로운 이름을 지정합니다.
df.columns.values[2:9] = ['PA', 'HIT', 'HR', 'Runs', 'RBI', 'BB', 'K']
# 해당하는 열만 선택하여 새로운 데이터프레임 생성
subset = df.iloc[:, 2:9]
# Seaborn의 PairGrid를 사용하여 그리드를 설정하고, 각 셀에 그래프를 그립니다.
g = sns.PairGrid(subset)
g.map_offdiag(sns.scatterplot) # 비대각선(상관 그래프)에 산점도
g.map_diag(sns.histplot) # 대각선(변수 분포)에 히스토그램
plt.show()
타수, 안타, 홈런, 득점, 타점, 볼넷, 삼진에 해당하는 값들을 PA, HIT, HR, Runs, RBI, BB, K로 바꿔준 다음 상관관계를 확인 해 보았습니다.
# 열 인덱스가 0부터 시작하므로 2에서 8까지의 열에 새로운 이름을 지정합니다.
df.columns.values[2:9] = ['PA', 'HIT', 'HR', 'Runs', 'RBI', 'BB', 'K']
# 해당하는 열만 선택하여 새로운 데이터프레임 생성
subset = df.iloc[:, 2:9]
# 상관계수 계산
correlation_matrix = subset.corr()
# 히트맵 생성
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, fmt=".2f", cmap='coolwarm', vmin=-1, vmax=1, square=True, cbar_kws={'shrink': .8})
plt.title('Correlation Matrix')
plt.show()
# 상관계수 매트릭스 계산
corr = subset.corr()
# 그래프 그리기
fig, ax = plt.subplots(figsize=(8, 6))
ax.set_xlim(0, corr.shape[1])
ax.set_ylim(0, corr.shape[0])
ax.set_xticks(np.arange(corr.shape[1]) + 0.5)
ax.set_yticks(np.arange(corr.shape[0]) + 0.5)
ax.set_xticklabels(corr.columns, rotation=45, ha='right')
ax.set_yticklabels(corr.index)
# 상관계수에 따라 원 그리기
for i in range(corr.shape[0]):
for j in range(corr.shape[1]):
circle_radius = np.abs(corr.iloc[i, j]) * 0.5 # 원의 크기는 상관계수의 절대값에 비례
if corr.iloc[i, j] > 0:
color = 'blue'
elif corr.iloc[i, j] < 0:
color = 'red'
else:
color = 'grey' # 상관계수가 0인 경우 회색으로 지정
circle = plt.Circle((j + 0.5, i + 0.5), circle_radius, color=color, alpha=0.5, edgecolor='black')
ax.add_artist(circle)
# 그리드와 라벨 숨기기
ax.grid(False)
plt.gca().invert_yaxis() # y축 반전
plt.title('Correlation Matrix with Circles')
plt.show()
원으로만 나오면 정확한 값을 알 수 없어서 값도 추가해 주었습니다.
# 상관계수 매트릭스 계산
corr = subset.corr()
# 그래프 설정
fig, ax = plt.subplots(figsize=(10, 8))
ax.set_xlim(0, len(corr.columns))
ax.set_ylim(0, len(corr.index))
ax.set_xticks(np.arange(len(corr.columns)) + 0.5)
ax.set_yticks(np.arange(len(corr.index)) + 0.5)
ax.set_xticklabels(corr.columns, rotation=45)
ax.set_yticklabels(corr.index)
# 각 셀에 원과 상관계수 값 표시
for i in range(len(corr.index)):
for j in range(len(corr.columns)):
value = corr.iloc[i, j]
circle_radius = np.abs(value) * 0.5 # 원의 크기 조절
circle_color = 'blue' if value > 0 else 'red'
circle = plt.Circle((j + 0.5, i + 0.5), circle_radius, color=circle_color, alpha=0.5, edgecolor=None)
ax.add_artist(circle)
text_color = 'black' if np.abs(value) < 0.5 else 'white'
ax.text(j + 0.5, i + 0.5, f"{value:.2f}", color=text_color, ha='center', va='center', fontweight='bold')
# 그리드 설정
ax.grid(False)
plt.gca().invert_yaxis() # y축 반전
plt.title('Correlation Matrix with Circles and Values')
plt.show()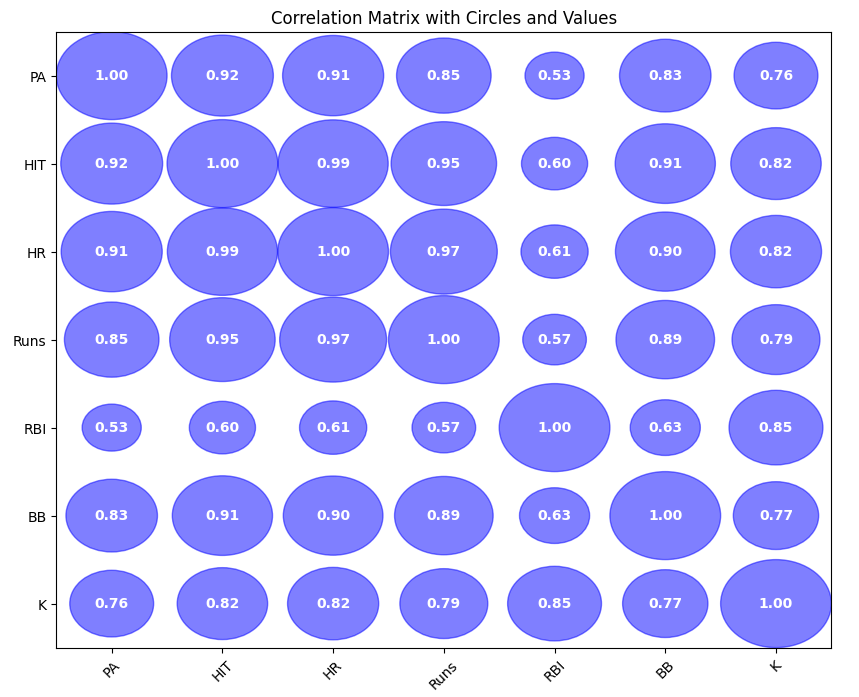
삼성 선수들 기록 분석
100명의 선수들 중 삼성 선수들의 기록을 확인해 보겠습니다.
samsung_stat= df[df['팀명'] == '삼성']
print(samsung_stat)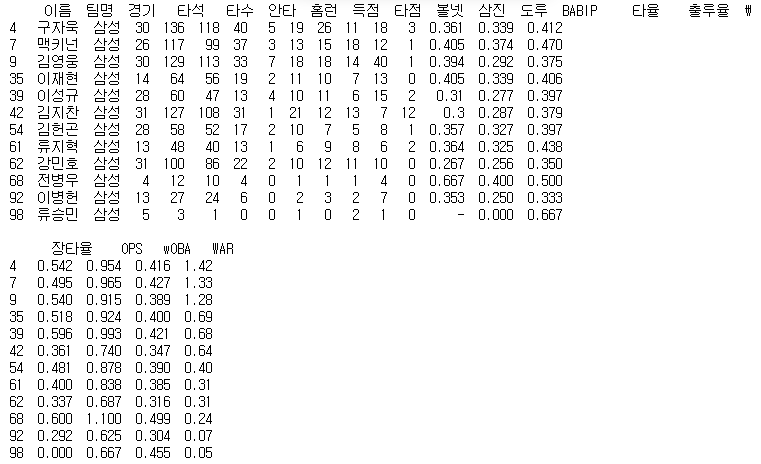
12명의 선수가 있는 것을 알 수 있고 이 선수들의 기록 중 출루율과 장타율을 이용해 산점도를 그려보겠습니다.
import matplotlib.pyplot as plt
import seaborn as sns
# '팀명'이 '삼성'인 선수들의 데이터 필터링
samsung_players = df[df['팀명'] == '삼성']
# seaborn을 사용하여 출루율과 장타율의 산점도를 그립니다.
sns.scatterplot(x='출루율', y='장타율', data=samsung_players)
# 산점도 제목과 축 이름 추가
plt.title('SL OBP & SLG scatter') #삼성 선수들 출루율 장타율 산점도
plt.xlabel('OBP') # 출루율
plt.ylabel('SLG') # 장타율
# 그래프 표시
plt.show()
어떤 선수의 기록인지 보기 어렵기 때문에 해당하는 선수의 이름이 찍히도록 추가해주었습니다.
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.font_manager as fm
# 나눔고딕 폰트 경로 설정
font_path = 'NanumGothic.ttf'
# 나눔고딕 폰트로 설정
font_prop = fm.FontProperties(fname=font_path)
plt.rcParams['font.family'] = font_prop.get_name()
# '팀명'이 '삼성'인 선수들의 데이터 필터링
samsung_players = df[df['팀명'] == '삼성']
# seaborn을 사용하여 출루율과 장타율의 산점도를 그립니다.
sns.scatterplot(x='출루율', y='장타율', data=samsung_players)
# 선수 이름 추가
for idx, player in samsung_players.iterrows():
plt.text(player['출루율'], player['장타율'], player['이름'], horizontalalignment='left', size='medium', color='black', weight='semibold', fontproperties=font_prop)
# 산점도 제목과 축 이름 추가
plt.title('삼성 선수 OBP & SLG scatter', fontproperties=font_prop)
plt.xlabel('출루율', fontproperties=font_prop) # 출루율
plt.ylabel('장타율', fontproperties=font_prop) # 장타율
# 그래프 표시
plt.show()
류승민 선수는 타석도 많이 없지만 볼넷으로 만 출루를 해 장탸율은 없는데 출루율이 0.65를 넘는 것을 볼 수 있고 나머지 선수드은 거의 다 3할 이상의 출루율과 장타율을 기록한 것을 볼 수 있습니다. 대부분의 타자들이 준수한 성적을 기록하고 있어 30경기정도 했지만 올 시즌 삼성이 잘 나가는 이유 중 하나인 것으로 보입니다.
'야구 분석 > Python' 카테고리의 다른 글
| 히트 스프레이 차트 만들어보기 (0) | 2024.05.18 |
|---|---|
| 놀란 아레나도 수비 지표 분석 (0) | 2024.05.15 |
| 24시즌 오타니와 베츠의 성적 비교 (0) | 2024.05.11 |
| 2023시즌 메이저리그 팀 순위 변화 (2) | 2024.05.08 |
| 24시즌 타자 기록 분석 (0) | 2024.05.01 |