시각화 주제
KBO가 개막한 지 한 달 정도가 지나고 다양한 기록들이 나왔습니다. 하루에 홈런을 세 방 친 선수도 있고, 9타석 연속 안타를 친 선수도 있었습니다. 각 팀당 30경기 정도를 했고 물론 타자들이 많은 타석을 나온 것은 아닙니다.
사실 최근 몇년 중에 삼성이 이렇게 상승세였던 적이 없어서........
그럼 24시즌 KBO 타자들의 타격 성적을 비교해 보겠습니다.
데이터 출처
현재 KBO선수들의 기록은 다양한 곳에서 찾아볼 수 있습니다. 이번에는 KBReport을 이용했습니다.
데이터 분석
분석 데이터 불러오기
사용할 데이터들을 불러오고 어떤 값들이 있는지 확인해보았습니다.
import pandas as pd
# 엑셀 파일 불러오기
df = pd.read_excel('2024_타자_기록.xlsx', engine='openpyxl')
# 데이터 확인
print(df.head())
print(df.info())print(df.columns)print(df.describe())데이터 전처리
이름이 겹치는 선수들이 있나 확인해 보겠습니다.
df_name = df['선수명'].value_counts()
print(df_name)Length가 100으로 나온 걸로 봐서 이름이 겹치는 선수는 없다는 것을 알 수 있습니다.
다음으로 각 팀에 몇 명씩 있는지 알아보겠습니다.
df_team = df['팀명'].value_counts()
print(df_team)
'#'에 해당하는 열을 삭제하고 '선수명'이라고 되어있는 열의 이름을 '이름'으로 변경해 주겠습니다.
# '#' 열 삭제
df.drop(columns='#', inplace=True)
# '선수명' 열의 이름을 '이름'으로 변경
df.rename(columns={'선수명': '이름'}, inplace=True)
print(df.columns)
print(df.describe())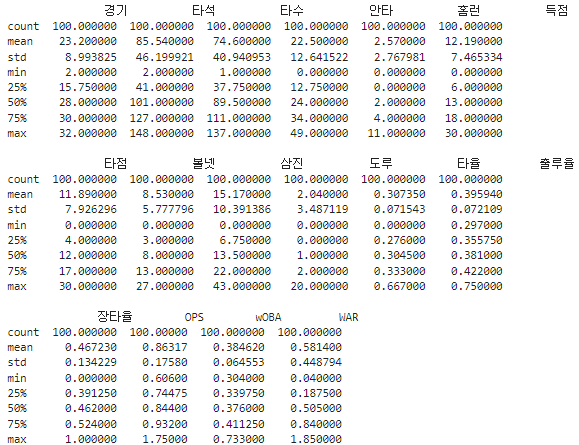
타석 분포 확인하기
가장 많이 들어온 선수의 타석 수와 가장 적게 들어온 선수의 타석 수를 확인하고 히스토그램을 그려보겠습니다.
min_value = df['타석'].min()
max_value = df['타석'].max()
print(min_value, max_value)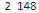
가장 적게 들어온 선수의 타석 수는 2이고 가장 많이 들어온 선수의 타석 수는 148입니다.
0부터 150으로 구간을 생성하고 20 간격으로 막대가 그려지도록 히스토그램을 그려주었습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 구간 생성
breaks = np.arange(0, 150, 20)
# 히스토그램 그리기
counts, bins, patches = plt.hist(df['타석'], bins=breaks, color='gray', edgecolor='black', rwidth=0.8)
# 각 막대 위에 빈도수 숫자 표시
max_height = 0 # 최대 높이 값을 저장하기 위한 변수
for count, patch in zip(counts, patches):
x = patch.get_x() + patch.get_width() / 2
y = patch.get_height() + 1
max_height = max(max_height, y) # 최대 높이 갱신
plt.text(x, y, str(int(count)), ha='center', va='bottom')
plt.title('PA Histogram')
plt.xlabel('PA')
plt.ylabel('Frequency')
# y축 범위 조정
plt.ylim(0, max_height + 3) # 최대 높이보다 추가 여백을 주어 모든 텍스트가 표시되도록 함
plt.show()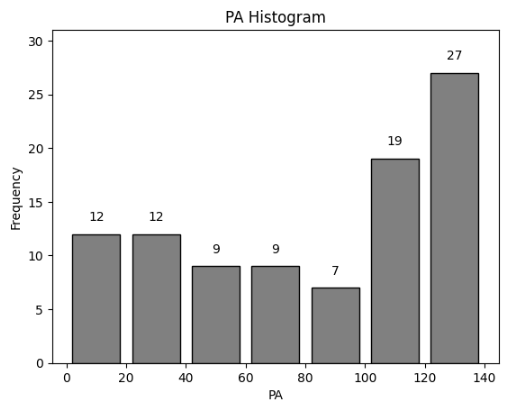
OPS 분포 확인하기
ops도 타석과 같이 최대 최소를 확인하고 히스토그램을 그려보았습니다.
min_value2 = df['OPS'].min()
max_value2 = df['OPS'].max()
print(min_value2, max_value2)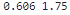
# 구간 생성
breaks = np.arange(0.5, 1.8, 0.3)
# 히스토그램 그리기
counts, bins, patches = plt.hist(df['OPS'], bins=breaks, color='gray', edgecolor='black', rwidth=0.8)
# 각 막대 위에 빈도수 숫자 표시
max_height = 0 # 최대 높이 값을 저장하기 위한 변수
for count, patch in zip(counts, patches):
x = patch.get_x() + patch.get_width() / 2
y = patch.get_height()
max_height = max(max_height, y) # 최대 높이 갱신
plt.text(x, y + 0.5, str(int(count)), ha='center', va='bottom') # 텍스트 위치 조절
plt.title('OPS Histogram')
plt.xlabel('OPS')
plt.ylabel('Frequency')
# y축 범위 조정
plt.ylim(0, max_height + 3) # 최대 높이보다 3 더 높은 값으로 상한 설정
plt.show()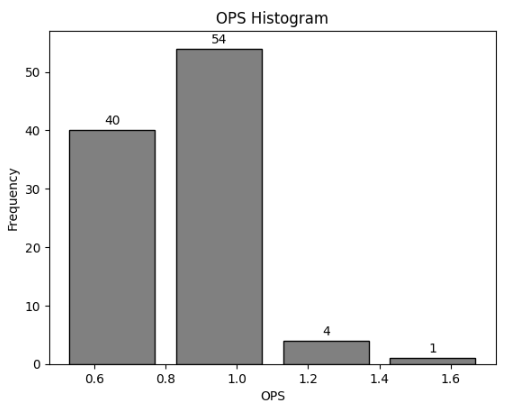
보통 ops가 0.9를 넘어가면 좋은 타자라고 할 수 있습니다. 그런데 1.1을 넘어가는 타자들이 5명이나 존재하는 것을 알 수 있습니다. 그래서 이 선수들이 누구인지 그 선수들의 ops가 얼마인지를 출력해 보았습니다.
# OPS를 기준으로 내림차순 정렬하고 상위 5명의 선수명과 OPS를 추출
top_players_ops = df.sort_values(by='OPS', ascending=False).head(5)[['이름', 'OPS']]
print(top_players_ops)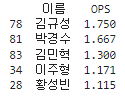
이름 옆에 보시면 이 선수들은 100명의 선수들 중 78, 81, 83등 상위권에 있는 선수들이 아닌 것을 알 수 있었고 이 선수들의 타석수가 얼마나 되는지를 알고 싶어서 타석도 추가해서 출력해 보았습니다.
top_players_ops = df.sort_values(by='OPS', ascending=False).head(5)[['이름', 'OPS', '타석']]
print(top_players_ops)
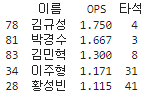
김규성 선수와 박경수 선수 김민혁 선수는 10타석도 들어가지 않은 것을 알 수 있었습니다. 상위 5명이 아닌 6~15등에 위치한 선수들은 누가 있나 출력해 보았습니다.
# OPS를 기준으로 내림차순 정렬하고 상위 6번째부터 15번째까지의 선수명과 OPS를 추출
top_players_ops2 = df.sort_values(by='OPS', ascending=False).iloc[5:15].loc[:, ['이름', 'OPS','타석']]
print(top_players_ops2)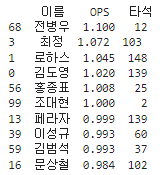
여기에서도 12타석인 선수도 있고 2타석인 선수들이 포함되어 있는 것을 알 수 있습니다. 그래서 100타석을 넘은 선수들 중 상위 10명의 선수는 누가 있나 출력해 보았습니다.
# 타석이 100타석을 넘은 선수 필터링
qualified_players = df[df['타석'] > 100]
# OPS를 기준으로 내림차순 정렬하여 상위 10명 선택
top_players = qualified_players.sort_values(by='OPS', ascending=False).head(10)
# 상위 10명의 이름, OPS, 타석 추출
top_players_info = top_players[['이름', 'OPS', '타석']]
print(top_players_info)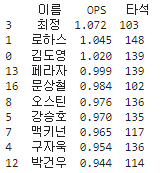
100타석 이상으로 조건을 주었더니 상위권에 있는 선수들이 ops에도 상위권에 있다는 것을 알 수 있었습니다.
'야구 분석 > Python' 카테고리의 다른 글
| 히트 스프레이 차트 만들어보기 (0) | 2024.05.18 |
|---|---|
| 놀란 아레나도 수비 지표 분석 (0) | 2024.05.15 |
| 24시즌 오타니와 베츠의 성적 비교 (0) | 2024.05.11 |
| 2023시즌 메이저리그 팀 순위 변화 (2) | 2024.05.08 |
| 24 시즌 타자 기록 분석 2 (2) | 2024.05.03 |