메이저리그 선수들의 WAR 예측하기 2
2024.06.30 - [취미] - 메이저리그 선수들의 WAR 예측하기 1 메이저리그 선수들의 WAR 예측하기 1주제메이저리그 선수들의 과거 데이터를 바탕으로 향후 선수 데이터를 예측하는 방법을 알아보겠습니
bbdiary03.tistory.com
이제 예측을 위한 데이터가 모두 준비되었고 예측을 해보겠습니다.
머신러닝으로 예측하기
def backtest(data, model, predictors, start=5, step=1):
all_predictions = []
years = sorted(data["Season"].unique())
for i in range(start, len(years), step):
current_year = years[i]
train = data[data["Season"] < current_year]
test = data[data["Season"] == current_year]
model.fit(train[predictors], train["Next_WAR"])
preds = model.predict(test[predictors])
preds = pd.Series(preds, index=test.index)
combined = pd.concat([test["Next_WAR"], preds], axis=1)
combined.columns = ["actual", "prediction"]
all_predictions.append(combined)
return pd.concat(all_predictions)
'backtest' 함수는 매우 중요한 함수입니다. 실제로 하는 일은 예측을 생성하는 것입니다. 일반적인 데이터셋에 대해 기계 학습 모델을 검증하는 데 사용하는 일반적인 교차 검증 방법에 익숙할 것입니다. 교차 검증에서 수행하는 작업은 데이터를 여러 그룹으로 분할한 후, 각각의 그룹을 테스트 세트로 사용하고 나머지 그룹을 훈련 세트로 사용하여 전체 데이터셋을 예측하는 것입니다.
하지만, 시계열 데이터를 다룰 때는 교차 검증을 다르게 접근해야 합니다. 시계열 데이터는 시간 순서가 중요하기 때문에, 미래 데이터를 사용하여 과거를 예측하는 일은 피해야 합니다. 이는 현실 세계에서 일어나는 일과 일치하지 않기 때문에 문제가 발생합니다. 예를 들어, 2024년에 무슨 일이 일어날지 예측하려면, 2024년 이후의 데이터는 사용할 수 없기 때문입니다. 따라서 과거 데이터를 사용하여 미래를 예측하는 방식으로 모델을 평가해야 합니다.
2003년부터 2023년까지 연도별로 돌며 현재 연도 이전의 데이터를 'train'으로 현재 연도의 데이터를 'test'로 설정해 줍니다. 만약 2007년의 데이터가 선택되면 2003 ~ 2006년까지의 데이터가 'train', 2007년의 데이터가 'test'가 됩니다.
그다음 'train' 데이터를 사용하여 모델을 훈련시키고 'test' 데이터를 사용하여 예측을 수행합니다. 실제 값과 예측 값을 결합하여 데이터 프레임을 만들고 'actual'과 'prediction'으로 준 후 'all_predictions' 리스트에 추가해 줍니다. 모든 연도에 대한 예측이 끝나면 원래 데이터 프레임으로 결합하도록 해주었습니다.
predictions = backtest(batting, rr, predictors)
predictions
이제 이 함수를 돌려보겠습니다. 'batting' 데이터셋을 사용하여 능선 회귀 모델로 예측을 수행해 줍니다.
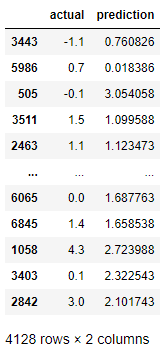
예측 결과를 보면 실제 WAR과 예측한 WAR 값이 나옵니다. 하지만 이 값들만으로는 알고리즘의 성능을 평가하기 어렵습니다. 알고리즘이 잘 작동하는지 확인하기 위해서는 오류 지표를 생성하고 요약 통계를 사용하는 것이 필요합니다.
from sklearn.metrics import mean_squared_error
mean_squared_error(predictions["actual"], predictions["prediction"])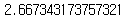
두열을 비교해 줄 것인데 실제 값에서 예측을 뺀 다음 차이를 비교하여 평균 제곱 오차를 계산해 줍니다. 2.667이 나오는 것을 알 수 있습니다. 이것이 정확한 값인지 확인하기 위해 한 가지 확인을 해보겠습니다.
batting["Next_WAR"].describe()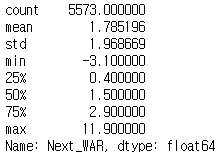
'Next_WAR'의 평균이 1.78이고, 표준편차가 1.96인 것을 확인할 수 있습니다. 위에서 구한 평균 제곱 오차 2.667의 제곱근이 표준편차 1.96보다 낮은 것이 좋습니다. 이는 모델이 표준편차보다 더 나은 예측을 수행하고 있음을 나타냅니다. 구체적으로, 2.6670975955295746의 제곱근은 1.6331251010040764로, 이는 표준편차 1.96보다 낮은 값을 가지므로 모델이 비교적 좋은 성능을 보이고 있음을 알 수 있습니다.
다음번에는 모델의 성능을 향상시키기 위한 몇 가지 방법을 시도해 보겠습니다. 현재는 플레이어가 현재 시즌에 어떻게 했는지에 대한 정보만 알고리즘에 제공하고 있습니다. 하지만, 플레이어가 이전 시즌에 어떻게 했는지에 대한 정보를 알고리즘에 제공하는 것도 유용할 수 있습니다. 예를 들어, 플레이어가 이전 시즌보다 WAR을 크게 개선했거나, 반대로 크게 하락했다고 가정해 보겠습니다. 플레이어가 쇠퇴하고 있을 수도 있으므로, 알고리즘에 플레이어의 과거 성과를 포함시키면 더 나은 예측을 할 수 있을 것입니다. 이를 통해 알고리즘이 플레이어의 성과 변화를 더 잘 이해하고, 미래 성과를 보다 정확하게 예측하는 데 도움이 될 수 있습니다.
'야구 분석 > Python' 카테고리의 다른 글
| 메이저리그 선수들의 WAR 예측하기 5 (0) | 2024.07.13 |
|---|---|
| 메이저리그 선수들의 WAR 예측하기 4 (0) | 2024.07.10 |
| 메이저리그 선수들의 WAR 예측하기 2 (1) | 2024.07.03 |
| 메이저리그 선수들의 WAR 예측하기 1 (0) | 2024.06.30 |
| 삼성 라이온즈 성적 크롤링하기 (1) | 2024.06.09 |