메이저리그 선수들의 WAR 예측하기 1
주제메이저리그 선수들의 과거 데이터를 바탕으로 향후 선수 데이터를 예측하는 방법을 알아보겠습니다. 이 선수가 팀 승리에 얼마나 공헌하였는지를 종합하여 표현하는 스탯인 WAR을 이용하여
bbdiary03.tistory.com
저번에 데이터를 가져왔다면 이번에는 머신 러닝 모델을 위해 준비를 마쳐주도록 하겠습니다.
데이터 중 유용한 특성 선택하기
저번에 만든 데이터를 보면 총 132개의 열이 있는데 이 132개를 모두 입력하고 싶지는 않습니다. 이러한 열 중 일부는 모델이 과적합되거나 다중 공선성 같은 다른 문제를 일으킬 수 있습니다. 그래서 실제로 모델 최적화에 도움이 되는 특성의 하위 집합을 선택할 수 있는 특성 선택기를 실행하려고 합니다. 정확도가 괜찮으므로, 먼저 특성 선택기와 함께 사용할 모델을 만들어야 합니다. 능선 회귀 모델을 사용할 것이며, 그 후 scikit-learn에서 SequentialFeatureSelector를 가져와 특성 선택기로 사용할 것입니다. 또한, 시계열 데이터를 처리하기 위해 TimeSeriesSplit을 사용할 것입니다.
from sklearn.linear_model import Ridge
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.model_selection import TimeSeriesSplit
rr = Ridge(alpha=1)
split = TimeSeriesSplit(n_splits=3)
sfs = SequentialFeatureSelector(rr,
n_features_to_select=20,
direction="forward",
cv=split,
n_jobs=8
)
먼저 능선 회귀 모델을 초기화하겠습니다. alpha 값을 높게 주면 능선 회귀 계수에 불이익을 주기 때문에 과적합이 줄어듭니다. 이 값을 낮게 설정하면 순수 일반 선형 회귀에 더 가까워지므로 바꿔가면서 어떤 효과가 있는지 확인할 수 있습니다.
split은 데이터를 세 부분으로 분할하고 해당 부분에 대해 예측하는 것입니다. 시계열 데이터의 순서를 유지하면서 교차 검증을 수행할 수 있습니다.
능성 회귀 모델을 사용하고 최종적으로 선택할 특성의 수를 20개로 설정해줍니다.forward로 특성을 하나씩 추가하면서 선택하도록 해주었습니다.
removed_columns = ["Next_WAR", "Name", "Team", "IDfg", "Season"]
selected_columns = batting.columns[~batting.columns.isin(removed_columns)]
실행하기 전에 몇 가지 작업을 해주어야 합니다. 가장 먼저 텍스트 열에서는 작동할 수 없기 때문에 텍스트 열을 지워주겠습니다. removed_columns에 포함되지 않은 모든 열들을 선택하여 selected_columns에 저장합니다. 이 과정을 통해 selected_columns에는 모델 학습에 사용할 중요한 열들만 남게 됩니다. 이를 통해 데이터 전처리를 수행한 후, 특성 선택 및 모델 학습을 진행할 수 있습니다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
batting.loc[:,selected_columns] = scaler.fit_transform(batting[selected_columns])
batting
능성 회귀 모델로 작업할 대 평균이 다음과 같도록 데이터 크기를 조정해야 합니다. 최소가 0이고 표준편차가 1이어야 모델이 효과적으로 작동합니다. MinMaxScaler를 이용해 데이터를 0과 1 사이의 범위로 정규화하는 데 사용됩니다. 나중에 열 간의 비율을 찾고 싶은데 scikit-learn의 표준 스칼라를 사용하면 음수값도 포함되기 때문에 MinMaxScaler를 사용해 주었습니다. scaler.fit_transform(batting [selected_columns])는 선택된 열에 대해 MinMaxScaler를 적용하여 데이터를 0과 1 사이의 값으로 변환합니다. fit_transform 메서드는 데이터를 스케일링할 때 사용되며, fit 단계에서는 데이터를 분석하여 각 특성의 최솟값과 최댓값을 계산하고, transform 단계에서는 이 계산된 값을 사용하여 데이터를 변환합니다.
제외해 준 값이 아닌 값들은 데이터가 변한 것을 볼 수 있습니다.
batting.describe()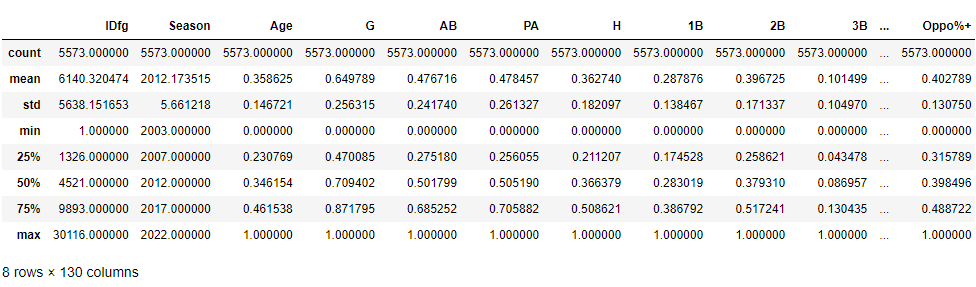
요약된 방법으로 보면, 나이의 최솟값이 0이고 최댓값이 1인 것을 보아 MinMaxScaler가 데이터를 확장한 것임을 알 수 있습니다. 이는 모든 값을 0과 1 사이로 조정했다는 의미입니다. 이제 데이터의 크기를 조정했으므로, 순차 특성 선택기를 실제로 적용하여 특성 선택기의 fit 메서드를 호출하겠습니다. 데이터에 피팅을 적용한다는 것은 능선 회귀 모델을 사용하여 가장 높은 정확도를 제공하는 20개의 예측 변수를 실제로 선택한다는 의미입니다.
sfs.fit(batting[selected_columns], batting["Next_WAR"])
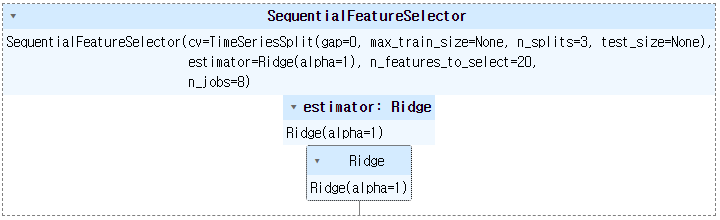
선택한 열을 전달한 다음 Next_WAR 값을 전달해줍니다.
sfs.get_support()
실행되면 순차 특성 선택기에서 실제로 예측 변수 목록을 추출할 수 있습니다. True는 우리가 선택하려는 열입니다.
predictors = list(selected_columns[sfs.get_support()])
predictors
열에 해당하는 값들을 불러와주었습니다.
'야구 분석 > Python' 카테고리의 다른 글
| 메이저리그 선수들의 WAR 예측하기 4 (0) | 2024.07.10 |
|---|---|
| 메이저리그 선수들의 WAR 예측하기 3 (0) | 2024.07.07 |
| 메이저리그 선수들의 WAR 예측하기 1 (0) | 2024.06.30 |
| 삼성 라이온즈 성적 크롤링하기 (1) | 2024.06.09 |
| 삼성 라이온즈 관중 수 시각화 (1) | 2024.06.05 |